
Gedurende sprint 9 kwamen enkele gebreken van het ontwerp boven water. Het huidige systeem was ontworpen voor een en dezelfde test. Als er een tweede test zou worden uitgevoerd zou deze in dezelfde tabel komen te staan.
Op dat moment zijn er enkele opties:
- je verwijdert alle data voor iedere sessie waardoor er geen filter nodig is.
- je past de tabel aan met een extra veld (de naam van de video). Deze naam gebruik je vervolgens in alle queries om het eindresultaat gefilterd terug te krijgen met de juiste data.
- je slaat de data op in een nieuwe tabel.
Het mag duidelijk zijn dat optie 1 eigenlijk helemaal geen optie is. Deze test wordt over meerdere dagen uitgevoerd waarbij het systeem ’s nachts uitgezet kan worden. Als dit gebeurt zouden de data iedere dag verwijderd worden en alleen de data van de laatste dag in gebruik zijn. Daarbij zou de data lokaal opgeslagen moeten worden om de verschillende versies te vergelijken. Als dit vergeten wordt dient de test opnieuw uitgevoerd te worden. Het is duidelijk dat dit totaal niet gebruiksvriendelijk is.
Optie 2 daarentegen is al gebruiksvriendelijker. De data kunnen gelijktijdig bestaan en de gebruiker kan de data blijven vergelijken zonder deze tussendoor te moeten opslaan. Hoewel de optie gebruiksvriendelijker is nemen de prestaties wel af. Onder het deelproduct Welk database-type past het best? is het in de Big-O Complexity chart overzichtelijk gemaakt hoe de hoeveelheid data de queries vertragen. Door alle data continu in dezelfde tabel te zetten wordt de tabel steeds groter en trager. Een gebruiker zal naarmate de hoeveelheid verschillende versies steeds langer moeten wachten.
Optie 3 die deze data splits naar verschillende tabellen heeft dit nadeel niet! Qua prestaties en gebruiksvriendelijkheid is optie 3 de beste keuze. Echter heeft optie 3 grote gevolgen voor het design.
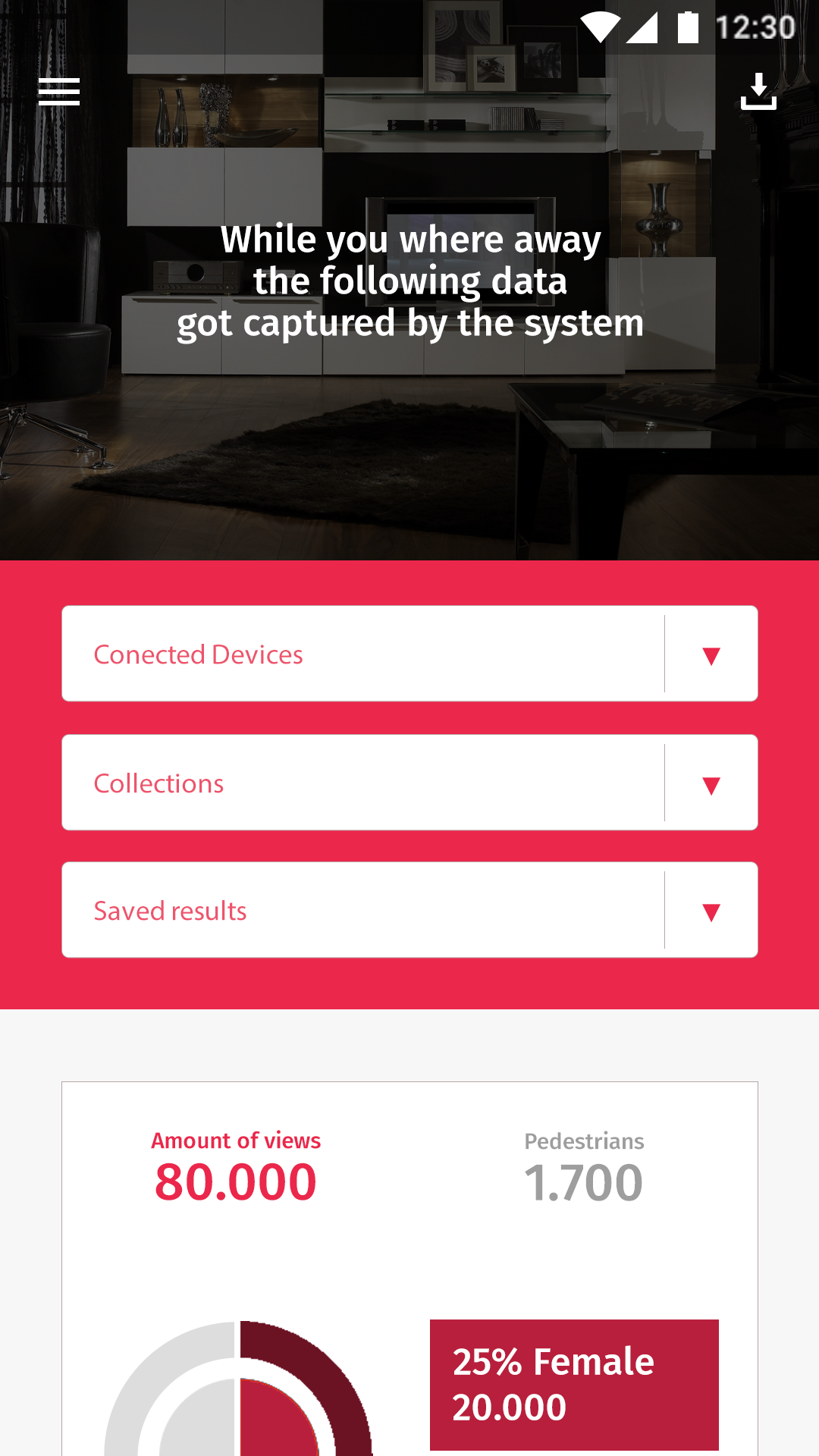
Het bestaan van meerdere tabellen en testen zorgt ervoor dat de gebruiker ook wat handelingen moet gaan uitvoeren. Zo zal de gebruiker een naam aan de testen moeten meegeven bij het starten van een test. Dit om te voorkomen dat data verkeerd opgeslagen worden. Daarbij zorgt deze naam er ook voor dat testen verspreid over meerdere dagen de data in dezelfde tabel opslaan. Behalve de wijziging bij het opslaan van data is de wijziging ook te merken bij het uitlezen van data. De gebruiker zal nu naast het aangesloten apparaat en de opgeslagen testen ook de juiste tabel op het opgeslagen apparaat moeten selecteren. Dit levert een heleboel selectievelden.
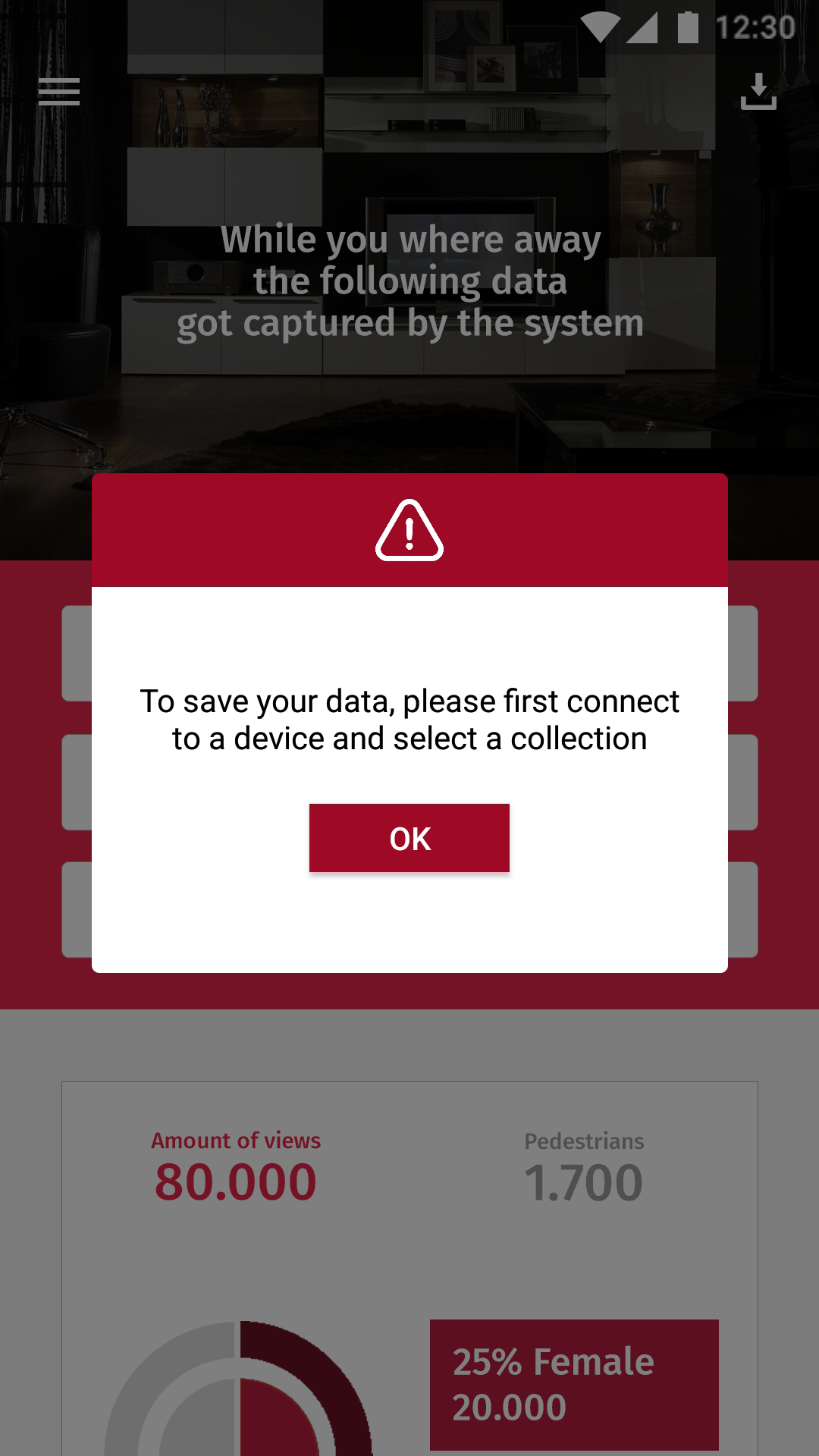
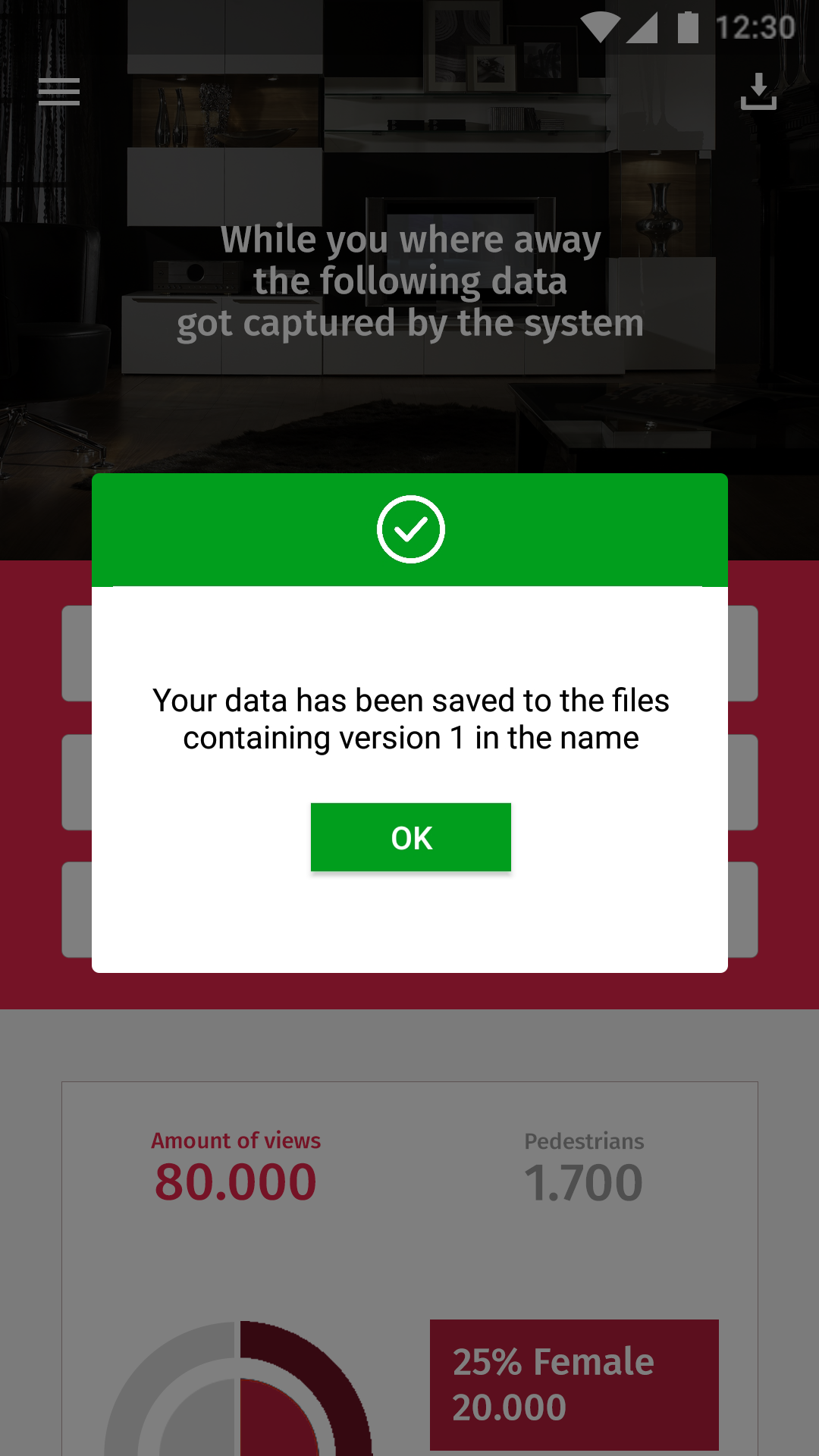
In het vorige design was nog geen rekening gehouden met tonen van opgeslagen data of het gebruik van meerdere tabellen. Deze wijzigingen zijn meegenomen in het nieuwe ontwerp. De input voor de naam, eveneens als de save button die een naam gebruikt, leveren voor de gebruiker een nieuwe verplichten velden op. Als deze velden niet ingevuld zijn dient de gebruiker genotificeerd te worden. Hiervoor zijn drie nieuwe notificatie/alerts/dialogs ontworpen om de gebruiker te informeren, alarmeren en corrigeren.
V2.
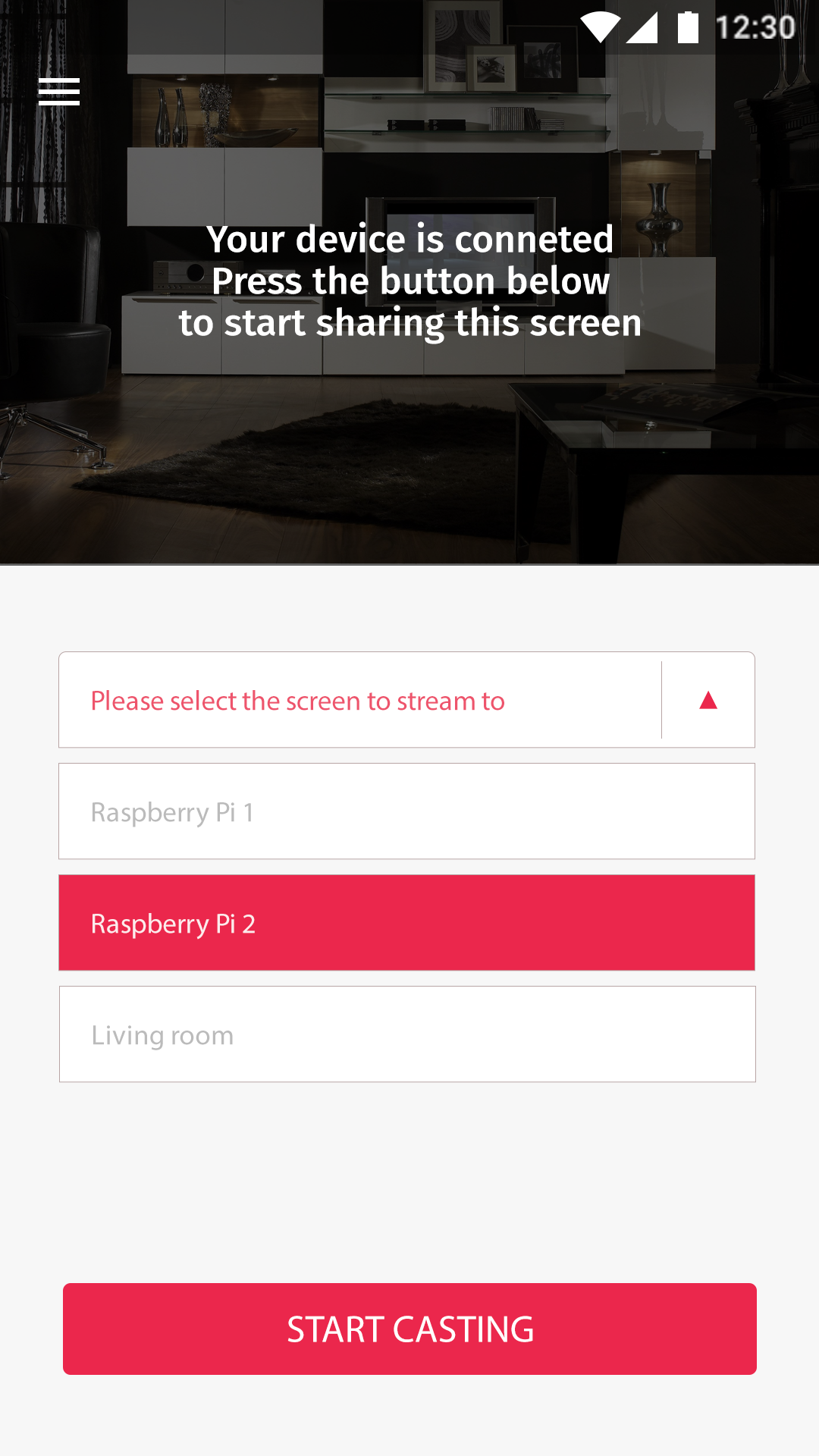
V3.
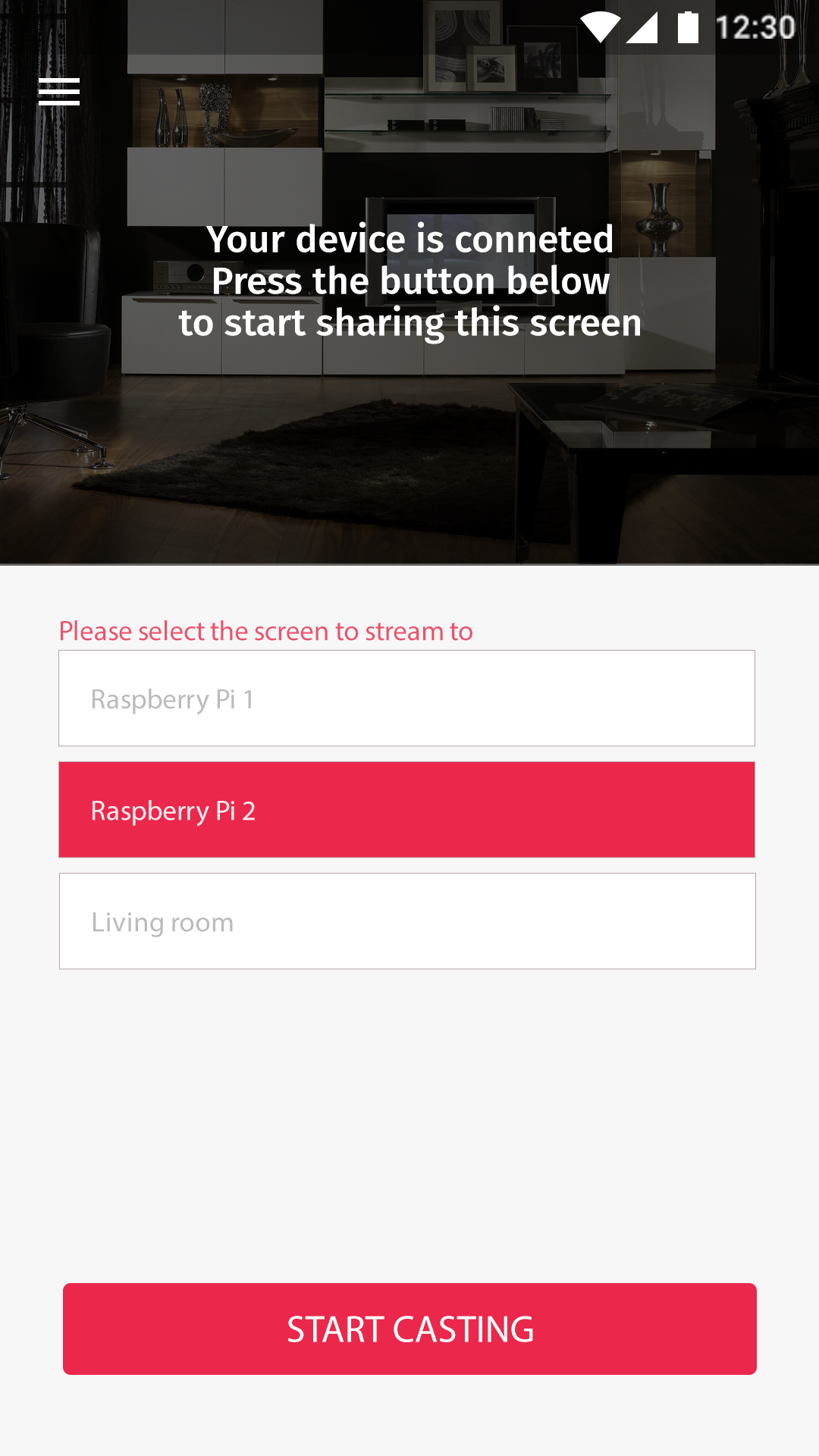
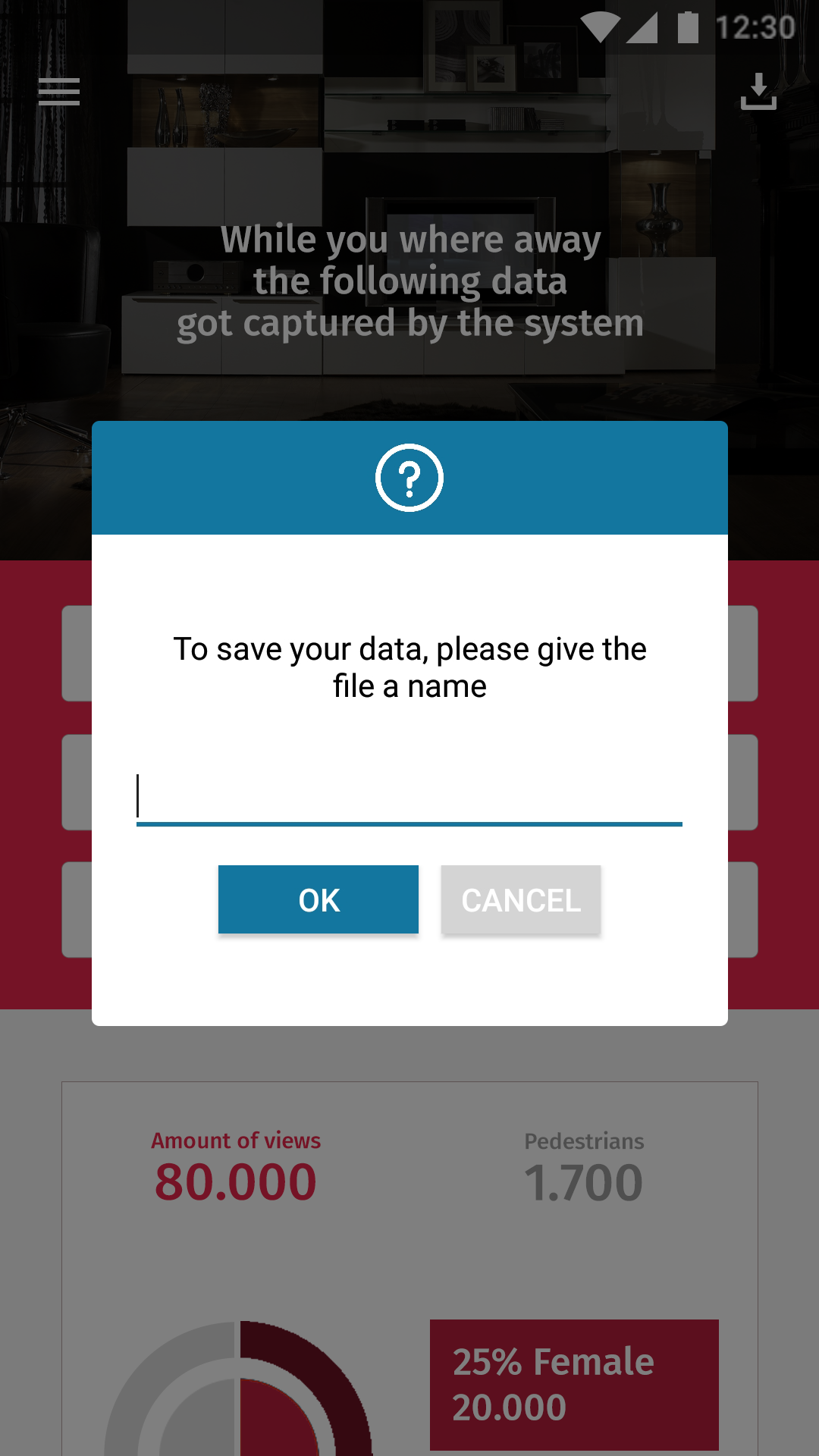
De bovenstaande schetsen leveren de onderstaande demo. Met deze demo kunt u gewoon interacteren met uw muis. Zodra u ergens klikt en er alleen blauwe vlakken verschijnen houdt dit in dat u ergens gedrukt heeft waar geen handeling aan vast zit of waar geen nieuw scherm voor geopend wordt. De blauwe vlakken die verschijnen zijn tevens alle interactieve punten waar u op kunt klikken en waarop handelingen volgen.
Dropdown
De dropdown in V2, te zien op het eerste scherm, is aangepast naar een listview. Dit omdat de kans op veel aangesloten apparaten minimaal is. Door de dropdown als listview te plaatsen hoeft de gebruiker minder handelingen te verrichten.
Meerdere tabellen
Zoals hierboven al eens vermeld werd leidde de technische wijzigingen tot aanpassingen in het design. Op het tweede scherm is te zien hoe het selecteren van het apparaat, de tabel of de opgeslagen data nu te selecteren zijn voor het vertoon ervan.
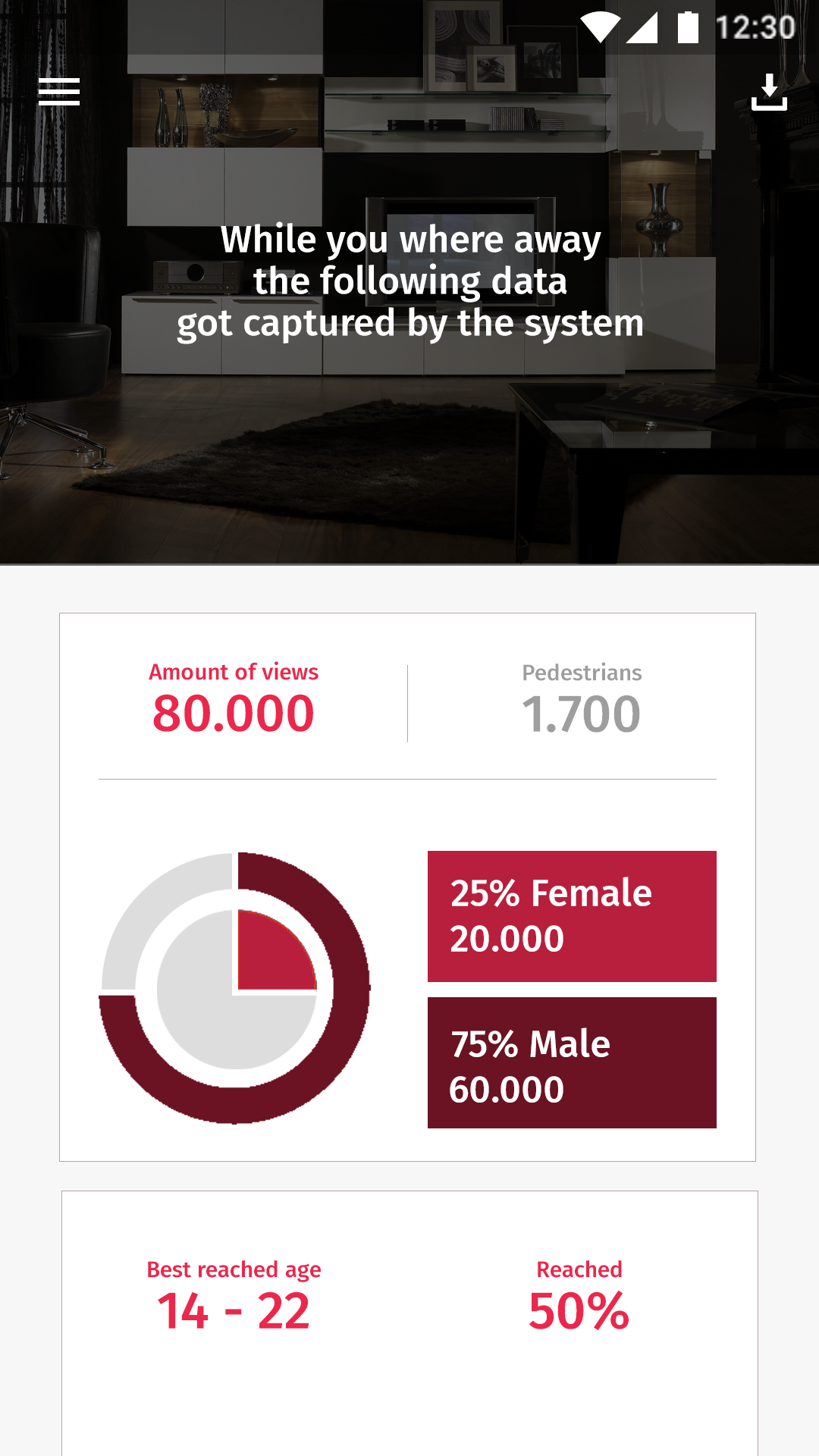
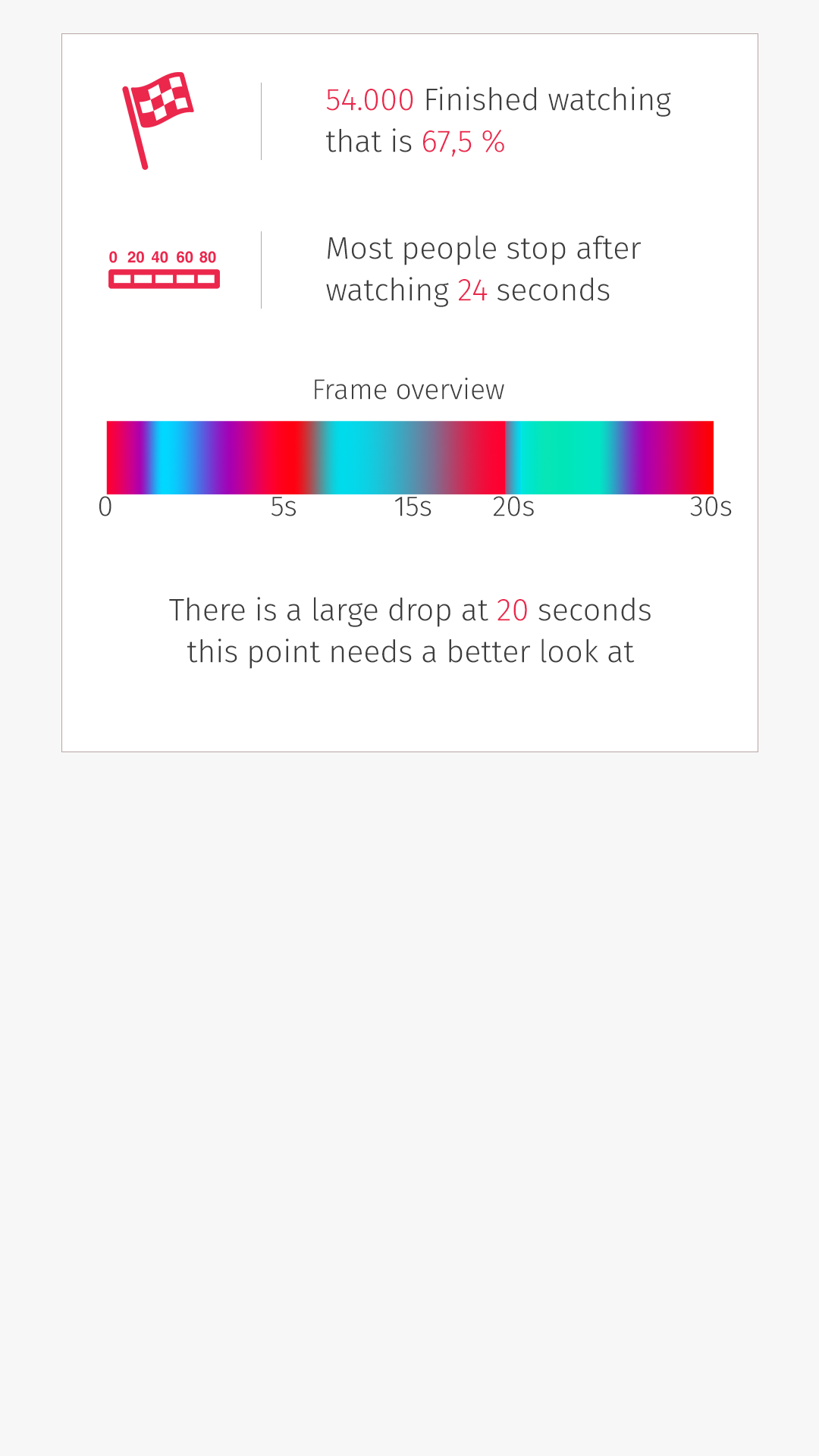
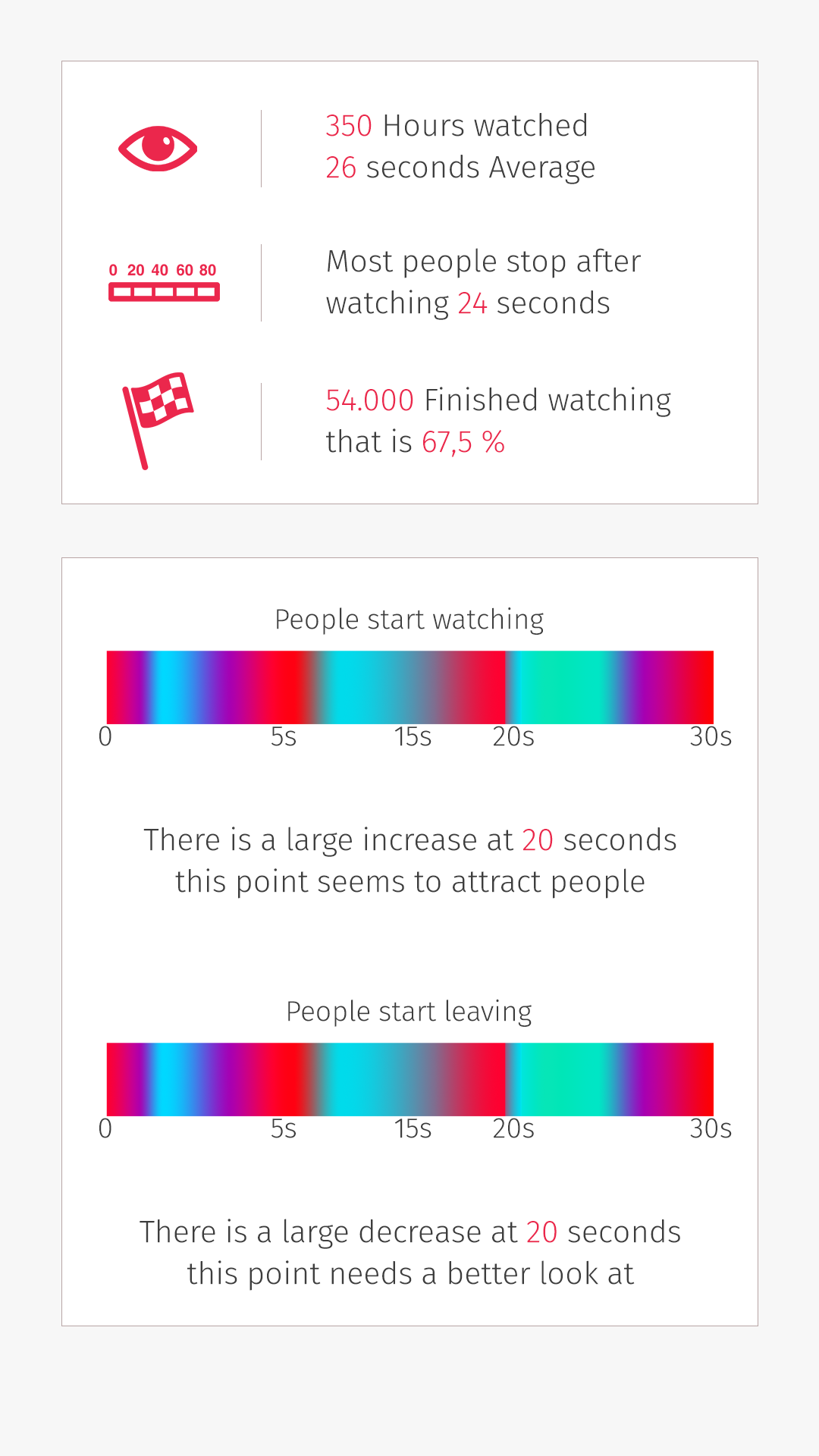
Heatmap
De originele heatmap had als nadeel dat deze vanaf een aantal gebruikers het gehele veld rood kleurt. Dit kwam omdat deze heatmap aantoont welke frames bekeken werden. Deze heatmap is vervangen door twee verschillende heatmaps. Deze twee heatmaps tonen de punten waarop gebruikers starten met kijken en stoppen met kijken. De kans dat de hele heatmap nu rood kleurt is een stuk kleiner omdat het nu punten betreft in plaats van een bereik.
Notificaties
In eerste instantie zat er geen terugkoppeling naar de gebruiker. Hierdoor had de gebruiker totaal geen idee of de bepaalde handeling succesvol was. Om de gebruiker te informeren over de status van de handeling zijn de drie notificaties toegevoegd. Deze notificaties zijn voorzien van kleur en icoon om de gebruiker sneller een idee te geven van de noodzaak van de notificatie.
Bibliografie
Babich, N. (2018). 10 Rules For Efficient Form Design. Retrieved from UX Planet: https://uxplanet.org/10-rules-for-efficient-form-design-e13dc1fb0e03
Babich, N. (2018). The Guide to Mobile App Design: Best Practices for 2018 and Beyond. Retrieved from Studio by UXPin: https://www.uxpin.com/studio/blog/guide-mobile-app-design-best-practices-2018-beyond/
Google. (2018). Dialogs . Retrieved from Material Design: https://material.io/design/components/dialogs.html
1 thought on “De invloed van code op het ontwerp”
Comments are closed.